2023. 2. 16. 00:41ㆍ💗 AI/💡 Theory
우리가 머신러닝 모델을 얘기 할 때 기본으로 항상 나오는 얘기가 바로 모델의 overfitting 및 underfitting이다.
우리는 모델을 학습할 때 새로운 인풋 데이터에 대해서 예측을 잘 하는, 즉 일반화가 잘 된 모델이 생성되기를 원한다.
모델이 일반화가 잘 되려면 모델이 다양한 데이터에 노출이 되어야 하고 모델 자체가 잘 짜여진 알고리즘이어야 한다.
먼저 용어들에 대해서 살펴보자
- Bias: 모델의 예측값과 실제 값 차이를 측정 한 값. 모델이 지나치게 단순화되면 예측 값이 실제 값과 멀어져서 더 큰 bias가 발생한다.
- Variance : 다양한 데이터셋의 예측값들이 얼마나 일관성 있는지, 또는 없는지를 측정한 값. 모델의 성능이 서로 다른 데이터셋에서 테스트 된다고 가정할 때, 예측값이 실제와 유사할 수록 variance(분산)이 작아진다. 즉, 분산이 높을 수록 모델이 일반화되지 못하였고 overfitting되었다고 말할 수 있다.
- Capacity : 모델의 형상을 나타낸 정도이다. 즉 capacity를 늘린다는 것은 layer를 더 deep하게 쌓거나 layer당 hidden unit 개수를 늘리는 등 학습 파라미터 수를 늘리는 것이다.

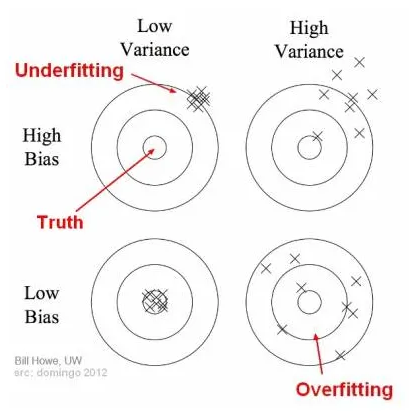
(우) https://towardsdatascience.com/understanding-the-bias-variance-tradeoff-165e6942b229
(왼) https://medium.com/geekculture/overfitting-underfitting-and-bias-variance-tradeoff-9e83f4a147c
💡Underfitting

- 정의 및 현상
- 학습 데이터셋에 대해서는 학습이 잘 되었지만 평가 데이터셋에 대해서는 잘 수행되지 않은 경우
- 즉, 새로운 데이터에 대해서 일반화가 잘 되지 않은 모델
- train loss & validation loss가 함께 감소하지만 원하는 모델의 성능에 도달하지 못하였을 경우
- 원인
- 데이터에 비해 모델이 너무 심플해서 발생
- 모델에 비해서 데이터가 너무 적을 경우 발생
- bias가 높고 variance가 낮을 때 : he algorithm outputs similar predictions for similar data, but predictions are wrong (algorithm “miss”).
- 학습데이터가 정제되지 않았고 노이즈가 많을 경우
- 해결 방안
- 모델의 복잡성 늘리기 (dropout 적용률 낮추기, convolution 커널 수, 레이어 수 늘리기)
- features의 수 늘리기
- 데이터에서 노이즈 제거하기
- 훈련 기간 늘리기 (에폭 수 증가시키기)
- (L2 regularization에서 λ의 값을 0에 가깝게 하면 정규화의 효과가 사라짐, L2 regularization은 본래 overfitting을 막는 용도)
- etc
💡Overfitting

- 정의 및 현상
- 모델이 너무 많은 데이터를 학습하다 보면 데이터셋의 노이즈와 부정확성을 학습을 하게된다. 이때 테스트 데이터로 평가 할 때 높은 분산값이 나타나고 정확하지 않은 예측을 하게 된다.
- 즉, 학습 데이터에만 지나치게 의존적으로 학습되어 새로운 데이터에 대해 잘 수행되지 않는 경우
- train loss는 작지만 validation loss가 큼
- 원인
- 낮은 bias, 높은 variance : the algorithm outputs very different predictions for similar data.
- 모델이 너무 복잡한 경우
- 모델에 비해서 데이터의 크기가 너무 큰 경우
- 해결 방안
- 학습 데이터 수 늘리기
- 모델은 데이터의 양이 적을 경우, 해당 데이터의 특정 패턴이나 노이즈까지 쉽게 암기하기 되므로 과적합 현상이 발생할 확률이 늘어납니다. 그렇기 때문에 데이터의 양을 늘릴 수록 모델은 데이터의 일반적인 패턴을 학습하여 과적합을 방지할 수 있습니다.[3]
- data augmentation
- 모델의 복잡성 줄이기 (capacity 줄이기)
- Early Stopping 적용, drop out 적용
- Regularization 적용 : weight decay
- batch normalization
- etc
- 학습 데이터 수 늘리기
References
[1] https://www.geeksforgeeks.org/underfitting-and-overfitting-in-machine-learning/
[2]https://towardsdatascience.com/overfitting-and-underfitting-principles-ea8964d9c45c
'💗 AI > 💡 Theory' 카테고리의 다른 글
| [모두팝] 생성모델부터 Diffusion 1회 내용 정리 (0) | 2023.10.05 |
|---|---|
| SoftNNloss ( Soft Nearest Neighbor loss ) (0) | 2023.04.01 |