2023. 10. 5. 14:32ㆍ💗 AI/💡 Theory
https://www.youtube.com/watch?v=vZdEGcLU_8U&t=122s
오늘 강의 하나로 GANs은 모두 마스터 불가능 합니다
이런 연구들이 있었구나. 저런 문제를 해결했구나
이런 자세로 들으면 된다
💡 Unconditional GAN
GAN이란 이미지를 생성하는 모델
training data의 distribution을 만들어내려고 함


<Discriminator training>
- real 샘플을 사용할 경우, 판별하는 Discriminator을 input으로 넣으면 , output(회색박스) 안의 logit값들이 모두 1이 되도록 loss를 지정 (L2, L1, 사용 가능 / cross entropy를 사용하는 이유는 틀린 샘플에 대해서 패널티를 강하게 걸음)
- fake 샘플(genearator가 가우시안 노이즈로부터 샘플링 한 것, latent z)을 input으로 받아서 이미지를 만들고, 그 이미지를 discriminator에 input으로 넣었을때, 그 아웃풋이 0이 되도록 discriminator의 loss를 지정

<Generator training>
- real과 fake를 분류하는 discrimiator를 이기기 위해서 학습 진행 / 본인이 생성한 이미지를 그 이미지를 discriminator에 넣었을 때 아웃풋으로 나온 logit이 모두 1이 되도록 loss를 걸어줌
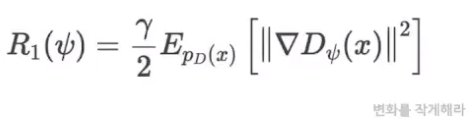
- 요즘은 이런 loss를 사용함
- 일반적인 GAN loss에 위의 Regularization을 더해줌 (R1 gradient penalty)
- Discriminator에 들어오는 input값들의 변화량을 작게 해주는 방향으로
💡 Conditional GAN

내가 원하는 이미지를 생성하기 위해서 additional information이 들어감




💡 HighResolution 시작

- 기존에는 256x256 이미지를 생성하겠다고 지정해놓고 시작
- 이 논문의 경우는 4x4 넣으면 8x8 이미지를 생성 .. 이런식으로 1024x1024 생성
- 현재는 안쓰이는 연구

- Conditional batch normalization : 기존에는 클래스를 concat했다면 batch normalization에 condition정보를 넣어줌
- Large scale : 채널, 배치 사이즈 늘려보자
- Truncation trick : 학습이 다 되고 나서 inference 시 트릭을 써서 샘플의 퀄리티를 향상시켜보자 (gaussian distribution에서 양 끝의 확률이 낮은 부분들을 잘라보자)

- 기존의 latent space z(가우시안 분포에서 샘플링한거)를 FC태워서 벡터로 만들자 (z->w)
- 데이터는 (a)형태로 분포되어있는데 그거를 가우시안 분포에 억지로 끼워넣으니까 학습이 잘 안되는 거 같다 ->(c)로 만듦

- 우리가 이제 mapping layers를 통해 w를 만들고, 이제 generator에 넣으면 condition에 잘 맞게 생성함


💡 Limited data, Application
데이터 개수가 적을 때 어떻게 할 것인지

- progressive training의 문제점
: 고개를 돌리면서 치아도 돌아가야하는데 치아는 고정되어있음
- AdaIN의 문제점
: 이미지 생성된 애들에 이상한 점? 영역들이 보임
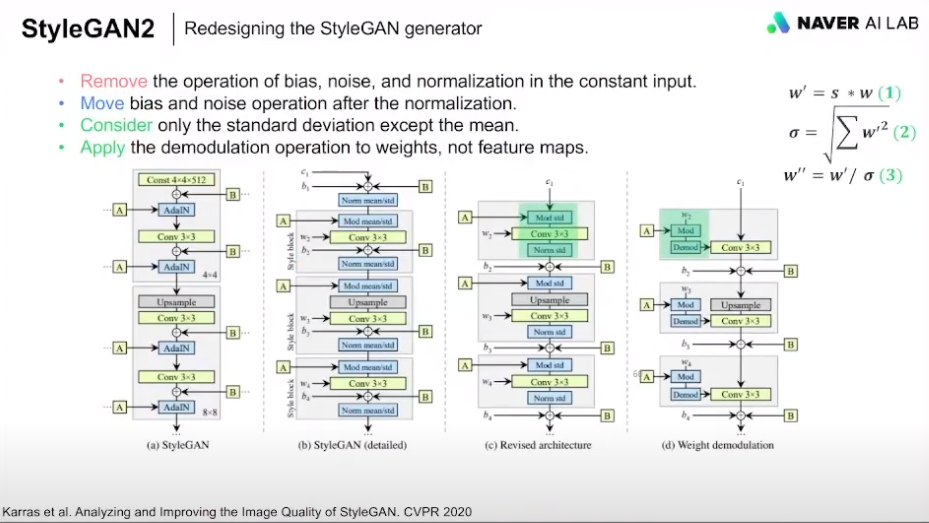
기존 (a)
(b) 처음 constant input에 대해서 이걸 삭제함
(c) B모듈(noise sum) 위치를 normalization 후로 바꿈, std만 사용해도 충분히 성능이 좋음
(d) feature map이 아니라 weight에 대해서 demodulation operation을 수행


- 적은 데이터에 대해서 어떻게 할 것인가

- Discriminator랑 Generator에 대해서 둘 다 augmentation을 하는게 좋음

- real 이미지만 augmentation을 하면 D는 augment image에 대해서 real이라고 판단
그럼 G는 augment 이미지가 real이라고 판단하게끔 augment된 이미지들을 생성하게 됨
- D만 augment 걸면 G가 augment되지 않은 이미지들은 판단을 잘 못하게 됨

- D의 오버피팅을 방지

-DiffAug 와 달리 매번 하지 않고 r의 값에 의해서 augmentation을 할지 말지 선택

💡 Limited data, Application
다 필요없고 Diffusion이 미래다
(다음 회차에)
💡

'💗 AI > 💡 Theory' 카테고리의 다른 글
| SoftNNloss ( Soft Nearest Neighbor loss ) (0) | 2023.04.01 |
|---|---|
| Overfitting(과적합), Underfitting(과소적합) 원인 및 해결 방법 (1) | 2023.02.16 |